A Colorful Hilbert Something or Other

To view the post on a separate page, click:
at
12/06/2008 10:37:00 AM (the permalink).
2 Comments
Links to this post
![]()
![]()
I take a conservative, evangelical, economistical look at things. I will be posting intermittently, for reference rather than daily reading. My Wordpress site from before 30 September 2007 is at http://rasmusen.org/x. It is searched from the search engine above.
To view the post on a separate page, click:
at
12/06/2008 10:37:00 AM (the permalink).
2 Comments
Links to this post
![]()
![]()

From Wikipedia's Smooth Functions:
"The class C0 consists of all continuous functions. The class C1 consists of all differentiable functions whose derivative is continuous; such functions are called continuously differentiable."
A differentiable function might not be C1. The function f(x) = x^2*sin(1/x) for x \neq 0 and f(x) =0 for x=0 is everywhere continuous and differentiablem, but its derivative is f'(x) = -cos(1/x) + 2x*sin(1/x) for x \neq 0 and f'(x) =0 for x=0, which is discontinuous at x=0, so it is not C1.
Labels: math
To view the post on a separate page, click:
at
11/09/2008 10:11:00 PM (the permalink).
0 Comments
Links to this post
![]()
![]()
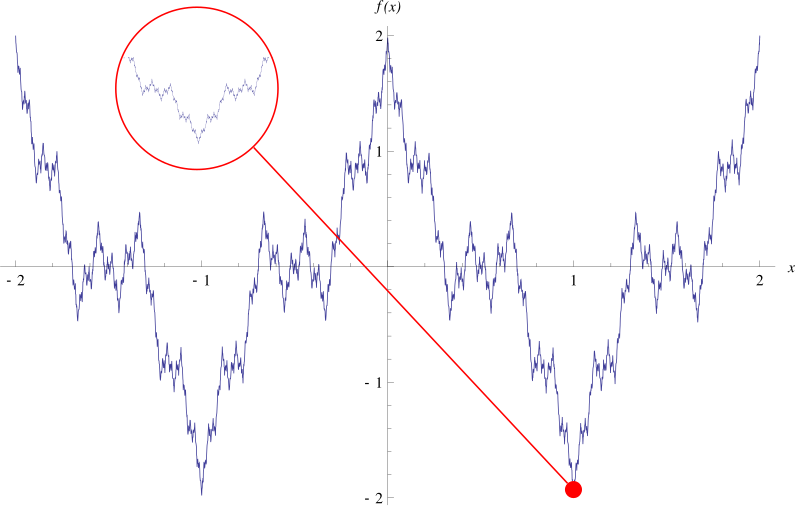 |
| The Weierstrass Function |
Do there exist monotonic functions that are everywhere continuous but nowhere differentiable?Do there exist monotonic functions that are nowhere continuous?
No in either case, it seems. Here is an answer:
First, monotone functions only can have a countable number of discontinuities (since these must be jump discontinuities where the function makes progress upward/downward and all uncountable positive sums are infinite).Moreover, for a more involved reason, the set of points where a monotone function is not differentiable must have lebesgue measure 0. (I.e. they are differentiable almost everywhere.)
One way to see this is from the fact that for an increasing function the limit of the slope of the secant line between (x,f(x)) and (x+h,f(x+h)) for each fixed x as h varies must always exist (and be nonnegative), provided we allow it to also take on the value +infinity. Then one can show this cannot be infinity except on a measure 0 set...again, the function would make too much progress.
On the other hand, the derivative can not exits on an uncountable set (e.g. the Cantor staircase function). Moreover, there is a slightly more sophisticated example of a strictly increasing continuous function that goes from f(0)=0 to f(1)=1 which has a derivative equal to 0 almost everywhere, in fact whenever the derivative exists.
Since they are differentiable almost everywhere, the derivatives of monotone functions are Lebesgue integrable functions (extend to the nondifferentiable points however you want, it won't affect the integral). So the previous example shows that the Fundamental Theorem of Calculus cannot be extended to even the class of derivatives of continuous monotone functions (even when the resulting derivative function is the constant function), since then we would have 0=\int_01 f'(x)dx=f(1)-f(0)=1. (The FTC does work, however, if f is continuous and the derivative exists except at a countable set).
From PlanetMathm here is Cantor's Staircase (in a 20-iteration figure, instead of infinite iterations), which uses a Cantor Set to build a function which is continuous and monotonic (strictly?) but with f'(x) =0 almost everywhere.
 |
| Graph of the cantor function using 20 iterations |
Labels: math
To view the post on a separate page, click:
at
11/08/2008 08:50:00 AM (the permalink).
0 Comments
Links to this post
![]()
![]()
October 25: Here are some key features of a quasiconcave function f(x).
Conjecture: Iff function f(.) is quasiconcave, there exists an increasing transformation g(.) such that g(f(.)) is concave.
I'd start to prove the conjecture this way. Let x and y be points in the upper level set of f(.), which means f(x)>=a and f(y)>=a. Since f(.) is quasiconcave, the upper level set is convex, which means that f(mx+ (1-m)y) >=a too. What we need to show first is that there exists some increasing function g() such that
g(f(mx+ (1-m)y)) >= mg(f(x)) + (1-m)g(f(y)). I think we need to start by assuming that f(x) \neq f(y), and that they are both on the boundary of that convex upper level set. Then we can see how g has to affect those two levels of f differently.
If the conjecture is true, then maybe we can think of quasiconcavity as being the equivalent of concavity for functions that are just defined on ordinal, not cardinal spaces.
October 26. Why, though, do we worry about quasi-concavity at all in economics? Why not just assume that utility functions are concave? The conventional answer would be that utility is ordinal, not cardinal. That is a bad answer for three reasons. First, even if it is ordinal, we could say, "It's only the ordinal properties of a utility function that affect decisions. Therefore, for convenience, let's say that whatever function you start with, you have to use a monotonic transformation to make it concave before we start working with it." Second, we might say, "Since only ordinal properties matter, let's assume utility is concave for convenience." Third, we might accept cardinality. Everybody uses von-Neumann Morgenstern cardinal utility in their models anyway, making only a brief nod, if any, to ordinality. But a risk-averse agent has concave utility. For these reasons, I wonder why it's worth making our graduate students learn about quasi-concavity. The opportunity cost is that they're not learning about something more useful such as the CAPM or the Coase Theorem.
Maybe quasi-concavity comes up in enough other contexts to be important. I know Rick Harbaugh has a paper on comparative cheap talk where it comes up. In Varian, it comes up first in production functions, where it allows you to have convex input sets for a given output without requiring diminishing returns to scale, as true concavity would.
October 27. Yet another thought. Margherita Cigola has done work on defining quasiconcavity in ordinal spaces, on lattices. Convexity has to be defined specially there. She uses a different (equivalent in R space) definition of quasiconcavity:
f(mx + (1-m)y) >= mf(x) + (1-m)f(y)
I like that because it is closer to the definition of concavity.
Or another, suitable when the function is differentiable: f is quasiconcave if whenever there is a maximum (i.e., the first derivatives are zero), the matrix of second derivatives is negative definite. MR suggested that, for the single-dimensional x case. I'm not sure it does generalize that way.
To view the post on a separate page, click:
at
10/24/2008 09:39:00 PM (the permalink).
0 Comments
Links to this post
![]()
![]()
The real importance of significant figures comes in doing arithmetic. If you run 100 yards in 11.71 seconds, and the 100 has three significant figures, then the speed should be written with three significant figures as 8.54 yards per second, not as 8.53970965 yards per second.
To view the post on a separate page, click:
at
10/21/2008 10:28:00 PM (the permalink).
0 Comments
Links to this post
![]()
![]()
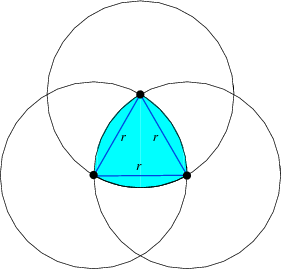 This Reuleaux Triangle from Wolfram/Mathematica is a nice idea for a shape. It is the shape a Wankel engine takes, perhaps because you can rotate this triangle inside a square as shown at the Wolfram site.
This Reuleaux Triangle from Wolfram/Mathematica is a nice idea for a shape. It is the shape a Wankel engine takes, perhaps because you can rotate this triangle inside a square as shown at the Wolfram site.
To view the post on a separate page, click:
at
10/08/2008 10:36:00 PM (the permalink).
0 Comments
Links to this post
![]()
![]()
 Dean Anton Sherwood has lots of good math graphics at http://www.ogre.nu/doodle/#chainmail. Here's one.
Dean Anton Sherwood has lots of good math graphics at http://www.ogre.nu/doodle/#chainmail. Here's one.
To view the post on a separate page, click:
at
7/24/2008 09:05:00 PM (the permalink).
1 Comments
Links to this post
![]()
![]()
Labels: math
To view the post on a separate page, click:
at
5/21/2008 06:12:00 AM (the permalink).
0 Comments
Links to this post
![]()
![]()
...Lipschitz continuity, named after Rudolf Lipschitz, is a smoothness condition for functions which is stronger than regular continuity. Intuitively, a Lipschitz continuous function is limited in how fast it can change; a line joining any two points on the graph of this function will never have a slope steeper than a certain number called the Lipschitz constant of the function....* The function f(x) = x^2 with domain all real numbers is not Lipschitz continuous. This function becomes arbitrarily steep as x goes to infinity. It is however locally Lipschitz continuous.
* The function f(x) = x^2 defined on [ − 3,7] is Lipschitz continuous, with Lipschitz constant K = 14.
Labels: math
To view the post on a separate page, click:
at
5/21/2008 06:06:00 AM (the permalink).
0 Comments
Links to this post
![]()
![]()
dy/y = exponent(beta)-1,
because log(y,D=0) = alpha and log(y, D=1) = alpha + beta, so
(y,D=1)/(y, D=0) = exp(alpha+beta)/exp(alpha) = exp(beta)
and
dy/y = (y,D=1)/(y, D=0) -1 = exp(beta)-1
This is consistent, but not unbiased. We know that OLS is BLUE, unbiased, as an estimator of the impact of the dummy D on log(Y), but that does not imply that it is unbiased as an estimator of the impact of D on Y. That is because E(f(z)) does not equal f(E(z)) in general and that ultimate effect of D on y, exp(beta)-1, is a nonlinear function of beta. Alexander Borisov pointed out to me that Peter Kennedy (AER, 1981) suggests using exp(betahat-vhat(betahat)/2)-1 as an estimate of the effect of going from D=0 to D=1, as biased, but less biased, and also consistent .
Labels: math, statistics
To view the post on a separate page, click:
at
1/09/2008 07:30:00 AM (the permalink).
0 Comments
Links to this post
![]()
![]()
I heard Adam Rosen give his paper, "Confidence sets for partially identified parameters that satisfy a finite number of moment inequalities." It stimulated some thoughts. (Click here to read more.)
Labels: math, statistics
To view the post on a separate page, click:
at
10/13/2007 06:56:00 PM (the permalink).
0 Comments
Links to this post
![]()
![]()
A standard counterintuitive result in statistics is that if the true model is logit, then it is okay to use a sample selected on the Y's, which is what the "case-control method" amounts to. You may select 1000 observations with Y=1 and 1000 observations with Y=0 and do estimation of the effects of every variable but the constant in the usual way, without any sort of weighting. This was shown in Prentice & Pyke (1979). They also purport to show that the standard errors may be computed in the usual way--- that is, using the curvature (2nd derivative) of the likelihood function. (Click here for more)
Labels: case-control method, frequentist, math, statistics
To view the post on a separate page, click:
at
10/08/2007 07:53:00 AM (the permalink).
0 Comments
Links to this post
![]()
![]()
At lunch at Nuffield I was just asking MM about some math notation I'd like: a symbol for "is not necessarily equal to". For example, and economics paper might show the following:
Proposition: Stocks with equal risks might or might not have the same returns. In the model's notation, x IS NOT NECESSARILY EQUAL TO y.
Labels: math, notation, statistics, writing
To view the post on a separate page, click:
at
10/04/2007 09:06:00 AM (the permalink).
4 Comments
Links to this post
![]()
![]()

Subscribe to
Posts [Atom]
 (or L) for Necessarily and
(or L) for Necessarily and  (or M) for Possibly."
(or M) for Possibly."